When I was a college student and took the course Data Structure and Algorithm, the B-Tree section was not included in the exam requirement. At that time the teacher just said little about it and therefore I knew little about it. It is ridiculous that I totally understand B-Tree until last month. So what is the B-Tree? B-Trees are balanced search trees designed to work well on magnetic disks or other direct-access secondary storage devices. B-Trees are similar to red-black trees. but they are better at minimizing disk I/O operations. Many database systems use B-Trees, or variants of B-Trees, to store information.
Category: Algorithm
Notes of Introduction to Algorithm(Red-Black Tree)
Posted by –
March 7, 2006
A red-black tree is a binary search tree with one extra bit of storage per node: its color, which can be either RED or BLACK.
A binary search tree is a red-black tree if it satisfies the following red-black properties:
1. Every node is either red or black.
2. The root is black.
3. Every leaf (NIL) is black.
4. If a node is red, then both its children are black.
5. For each node, all paths from the node to descendant leaves contain the same number of black nodes.
Binary Search Tree
Posted by –
January 12, 2006
Binary search tree is a binary tree in which each internal node x stores an element such that the elements stored in the left subtree of x are less than or equal to x and elements stored in the right subtree are greater than or equal to x. The following code is the class of binary search tree designed by me. I use a function pointer m_visit to construct the tree and visit the nodes of the tree.
template<typename T>
class BSTreeNode
{
public:
BSTreeNode(T d, BSTreeNode<T> *p=NULL, BSTreeNode<T> *l=NULL,
BSTreeNode<T> *r=NULL):data(d),parent(p),left(l),right(r){}
T data;
BSTreeNode<T> *parent;
BSTreeNode<T> *left;
BSTreeNode<T> *right;
};
template<typename T>
class BSTree
{
protected:
BSTreeNode<T> *m_root;
// A function pointer that points the visit function
typedef void (*v_func)(const T &data);
v_func m_visit;//the visit function pointer
void Inorder(BSTreeNode<T> *);//Inorder traversal of the tree
public:
BSTree(v_func f, BSTreeNode<T> *p=NULL): m_visit(f), m_root(p) {}
BSTreeNode<T>* GetRoot() { return m_root; } const
//inorder tree walk, thus prints a sorted list
void InorderWalk() { Inorder(m_root);}
//query on the binary search tree
BSTreeNode<T>* Search(const T &);
//find the successor of the given node in the sorted order which
//is determined by an inorder tree walk
BSTreeNode<T>* Successor(BSTreeNode<T>*);
//return the maximum element of the binary tree
const T& Maximum(void);
//return the minimum element of the binary tree
const T& Minimum(void);
//insert a new value into the binary search tree
void Insert(const T&);
//insert a new value with recursive version procedure
void Insert2(const T&, BSTreeNode<T>*);
//delete a node from the binary search tree
BSTreeNode<T>* Delete(BSTreeNode<T>*);
};
Let’s walk through the procedure of searching a given key in the above binary search data structure.
The procedure begins its search at the root and traces a path downward in the tree, and for each node it encounters, it compares the keys. If the searched key is bigger than the current key of the node, it goes down to left subtree. If the searched key is smaller than the current key of the node, it goes down to right subtree. If two keys are equal, the search terminates.
template<typename T>
BSTreeNode<T>* BSTree<T>::Search(const T &d)
{
BSTreeNode<T>* p = m_root;
while(p && p->data!=d)
{
if(p->data > d)
p=p->left;
else
p=p->right;
}
return p;
}
The structure of a binary search tree allows us to determine the In Order successor of a node without ever comparing keys. The following procedure returns the successor of a node x in a binary search tree if it exists, or NULL if x has the largest key in the tree.
template<typename T>
BSTreeNode<T>* BSTree<T>::Successor(BSTreeNode<T>* x)
{
//return the node x's successor if it exists.
if(!x)
return NULL;
BSTreeNode<T>* y=x->right;
//if x has right children, just return the leftmost node
//in the right subtree.
if(y)
{
while(y->left)
y=y->left;
return y;
}
//if x has no right child, then x's successor is the lowest
//ancestor of x
else
{ //whose left child is also an ancestor of x.
y=x->parent;
while(y && x!=y->left)
{
x=y;
y=y->parent;
}
return y;
}
}
An element in a binary search tree whose key is a minimum can always be found by following left child pointers from the root until a NULL is encountered, thus the procedure of finding the maximum element is symmetric.
template<typename T>
const T& BSTree<T>::Minimum()
{
BSTreeNode<T>* p = m_root;
while(p->left)
p=p->left;
return p->data;
}
template<typename T>
const T& BSTree<T>::Maximum()
{
BSTreeNode<T>* p = m_root;
while(p->right)
p=p->right;
return p->data;
}
To insert a node into a binary search tree, we use a node pointer x which begins at the root of the tree and traces a path downward. The pointer x traces the path, and the pointer y is maintained as the parent of x. These two pointers to move down the tree, going left or right depending on the comparison of the key to be inserted with x->data, until x is set to NULL. At that time, we use y to help us to insert the key. Insert2 is a recursive version of the insertion procedure.
template<typename T>
void BSTree<T>::Insert(const T& da)
{
BSTreeNode<T>* x=m_root,*y=NULL;
if(!x)//the tree is empty
m_root = new BSTreeNode<T>(da);
else
{
while(x)
{
y=x;//store x's parent;
if(da > x->data)
x=x->right;
else
x=x->left;
}//now y is the insertion node's parent
x = new BSTreeNode<T>(da);
x->parent=y;
if(da > y->data)
y->right=x;
else
y->left=x;
}
}
template<typename T>
void BSTree<T>::Insert2(const T& data, BSTreeNode<T>* z=NULL)
{
BSTreeNode<T>* x;
if(!z)
{
m_root = new BSTreeNode<T>(data);
return;
}
if(data > z->data && z->right)
Insert2(data,z->right);
if(data <= z->data && z->left)
Insert2(data,z->left);
if(!z->right && data > z->data)
{
x = new BSTreeNode<T>(data);
z->right = x;
x->parent = z;
}
if(!z->left && data < z->data)
{
x = new BSTreeNode<T>(data);
z->left = x;
x->parent = z;
}
}
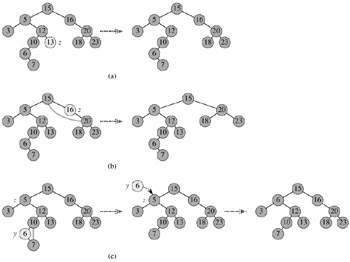
However, removing a node from a binary search tree is a bit more complex. Which node is actually removed is depends on how many children the node to be deleted has. If the node has one child then the child is spliced to the parent of the node, which means that we should remove the node itself. If the node has two children then its successor has no left child; copy the successor into the node and delete the successor instead. The following figure shows deleting a node z from a binary search tree. (a) z has no children, we just remove it. (b) z has only one child, we splice out z. (c) z has two children, we splice out its successor y, which has at most one child, and then replace z’s key and data with y’s key and data.
template<typename T>
void BSTree<T>::Delete(BSTreeNode<T>* z)
{
if(!z)
return NULL;
//y is the node should be removed, and x is the child of y
BSTreeNode<T> *y, *x;
//if z has 2 children, we should remove its successor
if(z->left && z->right)
y=Successor(z);
else//if z has 1 or no child, z itself should be removed.
y=z;
//Let x be the y's child and if y is the successor of z,
//notice that x has at most one child
if(y->left)
x=y->left;
else
x=y->right;
//begin to remove y from the tree
if(x)
x->parent=y->parent;
if(!y->parent)//if y is the root, let x be the root
m_root=x;
else
{
if(y==y->parent->left)
y->parent->left = x;
else
y->parent->right = x;
}
//if z has 2 children and we split out its successor
if(y!=z)
z->data=y->data;
delete y;
}
Finally, Here is the piece of code to test out my little binary search tree. The function print() visits the data of the tree node. The rand() function can generate random integers ranges from -999 to 999 approximately.
#include <iostream>
#include <time.h>
time_t* tp;
int randx =time(tp);
int rand()
{
randx = randx * 12345;
return randx % 1000;
}
static void print(const int& data)
{
cout<<data<<" ";
}
int main()
{
BSTree<int> bstree1(&print);
int i;
for(i=0;i<10;i++)
bstree1. Insertion(rand(),bstree1.GetRoot());
bstree1.InorderWalk();
cout<<endl;
int min=bstree1.Minimum();
int max=bstree1.Maximum();
cout<<"The minimum element is: "<<min<<endl;
cout<<"The maximum element is: "<<max<<endl; int secondmin=bstree1.Successor(bstree1.Search(min))->data;
cout<<"The second minimum element is : "<<secondmin<<endl;
int del=1;
while(del!=0){
cout<<"Choose an item to be deleted(Input '0' to quit):"; cin>>del;
if(bstree1.Delete(bstree1.Search(del)))
cout<<"Deletion Completed!n";
bstree1.InorderWalk();
cout<<endl;
}
return 0;
}
Notes of Introduction to Algorithm(Order Statistics)
Posted by –
January 10, 2006
The ith order statistic of a set of n elements is the ith smallest element. For example, the minimum of a set of elements is the first order statistic (i = 1), and the maximum is the nth order statistic (i = n). The asymptotic running time of the simple problem of finding a minimum or maximum is Θ(n). Yet select the ith smallest element appears more difficult but it also only need Θ(n) time.
Basic Operations on Binary Tree
Posted by –
January 10, 2006
Binary Tree is the most often used Data structure in the programming world and is also the basis of other complex data structures. So as a Computer Science student, it is very important to understand it thoroughly. The following paragraph is quoted by Standford Univ.’s Website explaining Binary Tree:
A binary tree is made of nodes, where each node contains a “left” pointer, a “right” pointer, and a data element. The “root” pointer points to the topmost node in the tree. The left and right pointers recursively point to smaller “subtrees” on either side. A null pointer represents a binary tree with no elements — the empty tree. The formal recursive definition is: a binary tree is either empty (represented by a null pointer), or is made of a single node, where the left and right pointers (recursive definition ahead) each point to a binary tree.
Notes of Introduction to Algorithm(Exercise 2.3.7)
Posted by –
December 19, 2005
The problem is:
Describe a Θ(n lg n)-time algorithm that, given a set S of n integers and another integer x, determines whether or not there exist two elements in S whose sum is exactly x.
Solution:
1.Sort the elements in S using merge sort.
2.Remove the last element from S. Let y be the value of the removed element.
3.If S is nonempty, look for z= x – y in S using binary search.
4.If S contains such an element z, then STOP, since we have found y and z such that x= y+ z. Otherwise, repeat Step 2.
5.If S is empty, then no two elements in S sum to x.
Step 1 takesΘ(n lg n) time. Step 2 takes Θ(1) time. Step 3 requires at most lg n time. Steps 2–4 are repeated at most n times. Thus, the total running time of this algorithm isΘ(n lg n). The following is my implement code:
ACM/ICPC
Posted by –
December 19, 2005
I often went to the ZOJ(Zhejiang University Online Judge)site to do some exercise before I took part in the Zhejiang Province Programming Contest. Attending this activity gives me much joy and my fellows in the contest and our coach are both very kind.
Select maximum and minimum using 3*(n/2) comparisons
Posted by –
December 16, 2005
It is not difficult to devise an algorithm that can find both the minimum and the maximum of n elements using Θ(n) comparisons. Simply find the minimum and maximum independently, using n – 1 comparisons for each, for a total of 2n – 2 comparisons.In fact, at most 3(n/2) comparisons are sufficient to find both the minimum and the maximum in the array of size n.We compare pairs of elements from the input first with each other, and then we compare the smaller to the current minimum and the larger to the current maximum, at a cost of 3 comparisons for every 2 elements.
Notes of Introduction to Algorithm(Counting Sort)
Posted by –
December 15, 2005
Counting sort assumes that each of the n input elements is an integer in the range 0 to k, for some integer k. When k = O(n), the sort runs in Θ(n) time. Seems so fast? The answer is no. It just uses extra space to cut down the runtime. However I have extended the range to -k to k in the following implementation.
Introduction to Algorithms
Posted by –
December 14, 2005
Recently I am reading the book CLRS Introduction to Algorithms, Second Edition. I find that I really hook on it! It’s a great book about the Algorithm and I think I will wirte some notes about reading the book and write some C/C++ code for the pseudo code on this book.
Notes of Introduction to Algorithm(Quick Sort)
Posted by –
December 14, 2005
Quicksort is a sorting algorithm whose worst-case running time is Θ(n^2) on an input array of n numbers. In spite of this slow worst-case running time, quicksort is often the best practical choice for sorting because it is remarkably efficient on the average: its expected running time is Θ(n lg n). Quicksort, like merge sort, is based on the divide-and-conquer method.
Notes of Introduction to Algorithm(Heap Sort)
Posted by –
December 8, 2005
Unlike the mergesort and quicksort, heapsort doesn’t require massive recursion or multiple arrays to work and the time complexity of heapsort is O(n log(n)) . It utilizes a special data structure called heap. Before we take a look at the Heap sort algorithm, let’s explain the the (binary) heap data structure.